Kafka
Kafka基本概念
- 概念:Kafka是一个分布式流处理平台
- 特性:
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
传统的系统交互:
- HTTP
- RPC
- 基于消息系统(生产者 -> 消息系统 -> 消费者)
Kafka 核心概念
- Topic:以分类的方式来存储,这个分类就叫topic
- 一种类别,表示要发送给谁
- 有多个订阅者订阅一个主题
- 系统Topic “__consumer_offsets” 用来管理消费者的消费偏移量
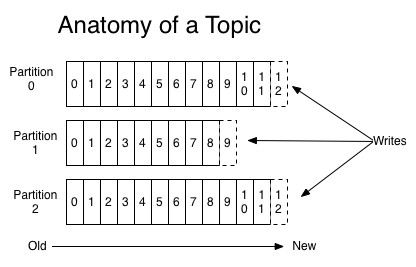
- Partition:分区;一个Topic有多个分区。在一个分区上消息是严格顺序的,多个分区是无序的。每个分区都有一个leader和零个或多个follower。leader负责读写请求。follower负责副本的复制。Kafka默认创建50个分区
- Segment(段):一个分区包含多个segment,取决于消息的数量,分区的物理存储
- 一个partition是有一系列有序、不可变的消息所构成的。一个partition的消息数量可能会非常多,因此显然不能将所有的消息都保存到一个文件当中。因此,当partition中的消息数量增长到一定程度之后,消息文件会进行切割,新的消息会被写到一个新的文件当中,当新的文件增加到一定程度后,新的消息又会被写到另一个新的文件中,以此类推;这一个个新的数据文件我们就称之为segment(段)
- 因此,一个partition在物理上是由一个或者多个segment所构成的。每个segment中则保存了真实的消息数据
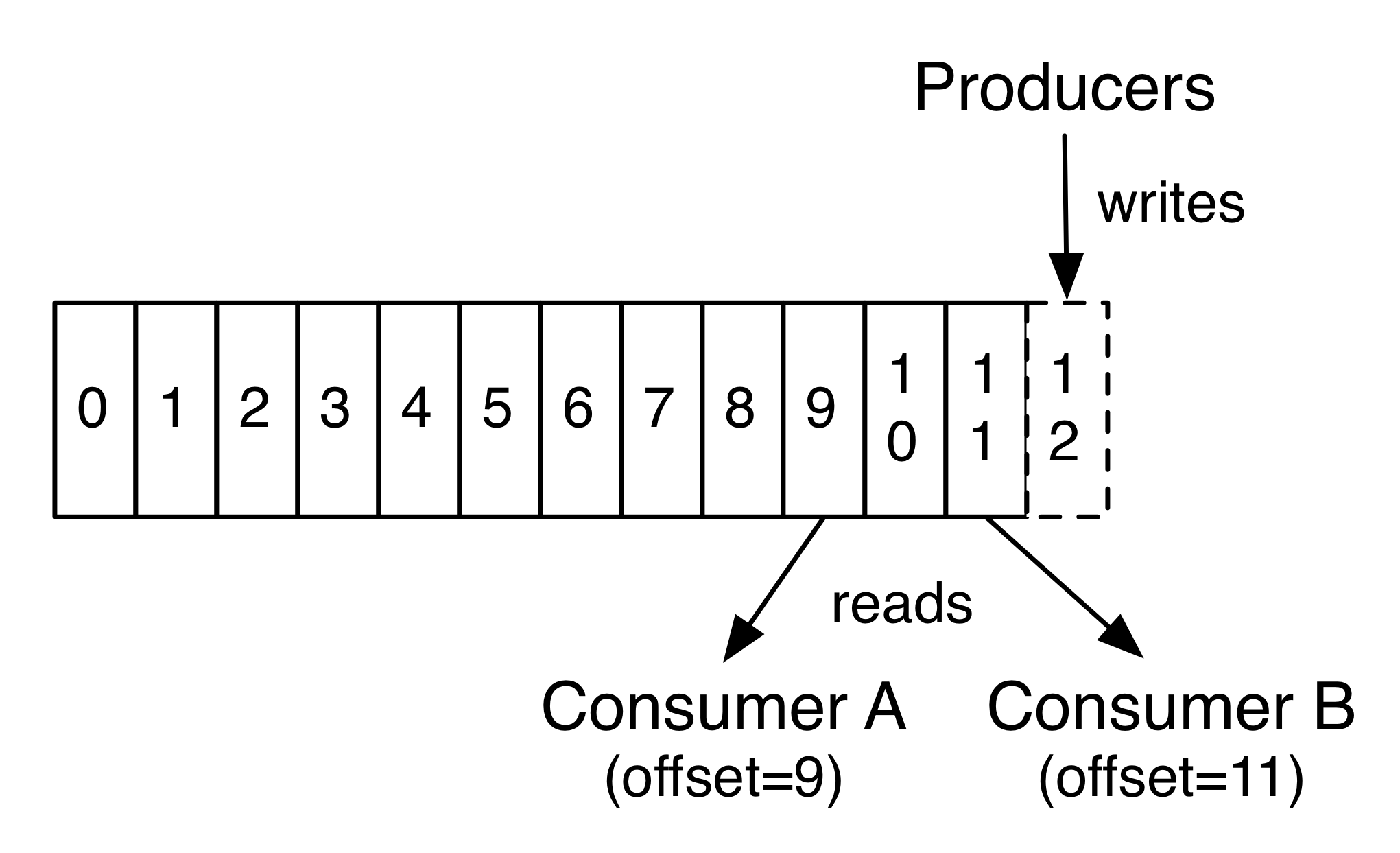
- Offset:表示分区中的消息记录的偏移量,用来标识每一条记录
- Replicate:副本,用于实现容错
- Producer:消息生产者,负责选择发送到topic的哪一个分区
- Consumer
- 消费者组:逻辑概念,包含零个或者多个消费者;负责订阅主题接收消息,并分给消费者进行消费
- 消费者:消息消费者,负责处理消息
- 如果所有的消费者实例拥有相同的消费者组,那么将进行负载均衡消费
- 如果所有的消费者实例属于不同的消费者组,那么将进行广播消费
- 消息组成:Key、Value、timestamp
- 集群:多个Broker组成的一个整体
- 控制器(controller): 集群中选取一个broker担任controller
- 通过配置来设置消息的保留时间,默认是7天。Kafka性能和数据量大小无关
Kafka Api
- Producer API (publish message)
- Consumer API (subscribe message)
- Streams API (让应用成为流处理器,处理完了然后可以输出出去)
- Connector API (连接API)
Kafka流式处理
- 持续接收数据输入流
- 然后输出到输出流
Kafka分区
- 每个分区都是一个有序的、不可变的消息序列。后续新来的消息会源源不断的持续追加到分区的后面,类似于Git的提交日志
- 分区中的每一条消息都会分配一个连续的id值(即offset),这个值用于标识唯一的分区中的每一条消息
- 每个topic可以指定不同的分区数量
分区的作用
- 分区中的消息数据是存储在日志文件中的,而且同一分区中的消息数据是按照发送顺序严格有序的。分区在逻辑上对应一个日志,当生产者将消息写入分区中时,实际上是写到了分区所对应的日志当中。而日志可以看做是一种逻辑的概念。它对应于磁盘上的一个目录,一个日志文件由多个Segment(段)来构成,每个Segment对应于一个索引文件与一个日志文件
- 借助于分区,我们可以实现Kafka Server的水平扩展,对于一台机器来说,无论是物理机还是虚拟机,其运行能力总归是有限的,当一台机器到达其能力上限时就无法再扩展了,即垂直扩展能力总是受到硬件制约的。通过使用分区,我们可以将一个主题中的消息分散到不同的Kafka Server上(Kafka集群),这样当机器能力不足时,我们只需要添加机器就可以了,在新的机器上创建新的分区,这样理论上就可以实现无限的水平扩展能力。 3.分区还可以实现并行处理能力,向一个主题所发送的消息会发送给该主题所拥有的不同的分区中,这样消息就可以实现并行发送与处理,由多个分区来接收所发送的消息
关于partition和segment之间的关系
- 每个partition都相当于一个大型文件被分配到多个大小相等的segment数据文件中,每个segment中的消息数量未必相等(这与消息大小有着紧密的关系,不同的消息所占据的磁盘空间是不一样的),这个特点使得老的segment文件可以很容易被删除掉,有助于提升磁盘的利用效率
- 每个分区只需要支持顺序读写即可,segment文件的生命周期是由Kafka Server的配置参数所决定的,比如说,server.properties文件中的 log.retention.hours=168 属性,就是7天
分区目录下的文件格式
- index : 他是segment文件的索引文件,他是log数据文件成对出现的
- log : 他是segment文件的数据文件,用于存储实际的消息,segment文件命名规则是partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,没有数字则用0表示
- timeindex : 基于消息日期的索引文件,主要用途是一些根据日期来寻找消息的场景下使用,此外在基于时间的日志rolling或是基于时间的日志保留策略等情况下也会使用,实际上该文件是基于时间戳的索引文件
- leader-epoch-checkpoint : 是leader的一个缓存文件,实际上,它是与Kafka的HW(High Water)与LEO(Log End Offset)相关的一个重要文件
Kafka常用脚本
- 创建主题:
./kafka-topics.sh --create --topic myTest1 --replication-factor 1 --partitions 1 --bootstrap-server localhost:9092 - 显示已有主题列表:
./kafka-topics.sh --list --bootstrap-server localhost:9092 - 显示某个主题的详情:
./kafka-topics.sh --describe --topic myTest1 --bootstrap-server localhost:9092 - 开启生产者,发送消息:
./kafka-console-producer.sh --topic myTest1 --broker-list localhost:9092 - 开启消费者:
./kafka-console-consumer.sh --topic myTest1 --bootstrap-server localhost:9092 --from-beginning(–from-beginning参数指定要从头开始消费) --group myGroup用于指定消费者组,同一个消费者组消息是集群消费
Kafka配置参数
auto.create.topic.enable = true当主题不存在的时候,Kafka默认创建主题.delete.topic.enable默认为true。如果设置为false,那么删除主题将无效