JDK8 HashMap实现原理
1. 存储结构
- 数据结构:数组+链表/红黑树
- 使用常量 TREEIFY_THRESHOLD 来控制是否切换到平衡树来存储。目前,这个常量值是8,这意味着当有超过8个元素的索引一样时,HashMap会使用树来存储它们。
2. Hash冲突
- 产生原因:HashMap中调用hashCode()方法来计算hashCode。由于在Java中两个不同的对象可能有一样的hashCode,所以不同的键可能有一样hashCode,从而导致冲突的产生。
- 解决冲突:当冲突节点数不小于8-1时,转换成红黑树。
- HashMap在处理冲突时使用链表存储相同索引的元素。
- 当同一hash桶中的元素数量超过特定的值便会由链表切换到平衡树
- 红黑树转换过程
3. 初始化和扩容
- 初始化:当调用new HashMap()时 :
public HashMap() { // DEFAULT_INITIAL_CAPACITY 默认的初始化容量为16 // DEFAULT_LOAD_FACTOR 默认的负载因子默认为0.75f this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); } - 扩容
- 什么时候需要扩容:HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组。
- 创建一个新的Entry空数组,长度是原数组的2倍。
- 遍历原Entry数组,把所有的Entry重新Hash到新数组。
4. 源码分析
- put操作:将指定的值与此映射中的指定键相关联。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 如果当前map中无数据,执行resize方法。并且返回n if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 如果要插入的键值对要存放的这个位置刚好没有元素,那么封装成Node对象,放在这个位置上 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // 否则的话,说明这上面有元素 else { Node<K,V> e; K k; // 如果这个元素的key与要插入的一样,那么就替换。 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //1.如果当前节点是TreeNode类型的数据,执行putTreeVal方法 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 遍历链表的数据 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 2.判断链上的数据长度,如果大于红黑树的条件,执行treeifyBin() if (binCount >= TREEIFY_THRESHOLD - 1) // treeifyBin()就是将链表转换成红黑树。 treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; //判断阈值,决定是否扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }一图胜千言(以下图片来自知乎):
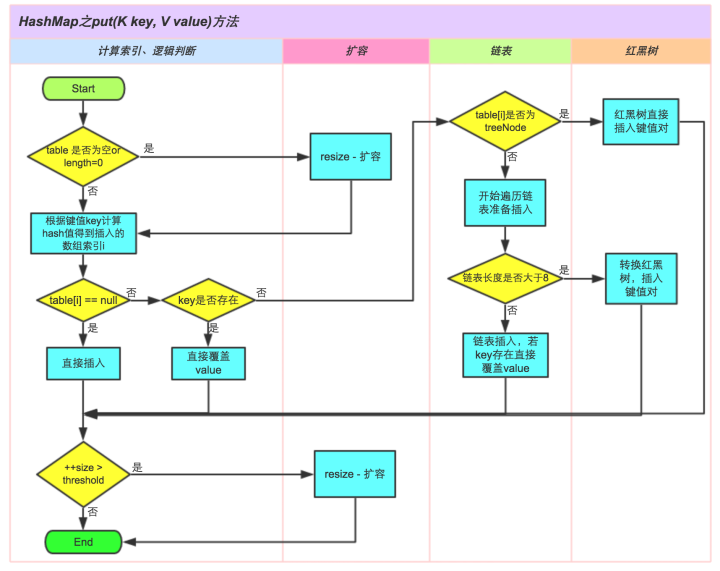
- get操作
- resize操作
5. HashMap和HashTable的区别
- HashMap:
- 线程不安全的
- 允许有null的键和值
- 效率较高
- HashTable
- 线程安全的,使用了Synchronized来进行方法同步
- 不允许有null 的键和值
- 效率较低